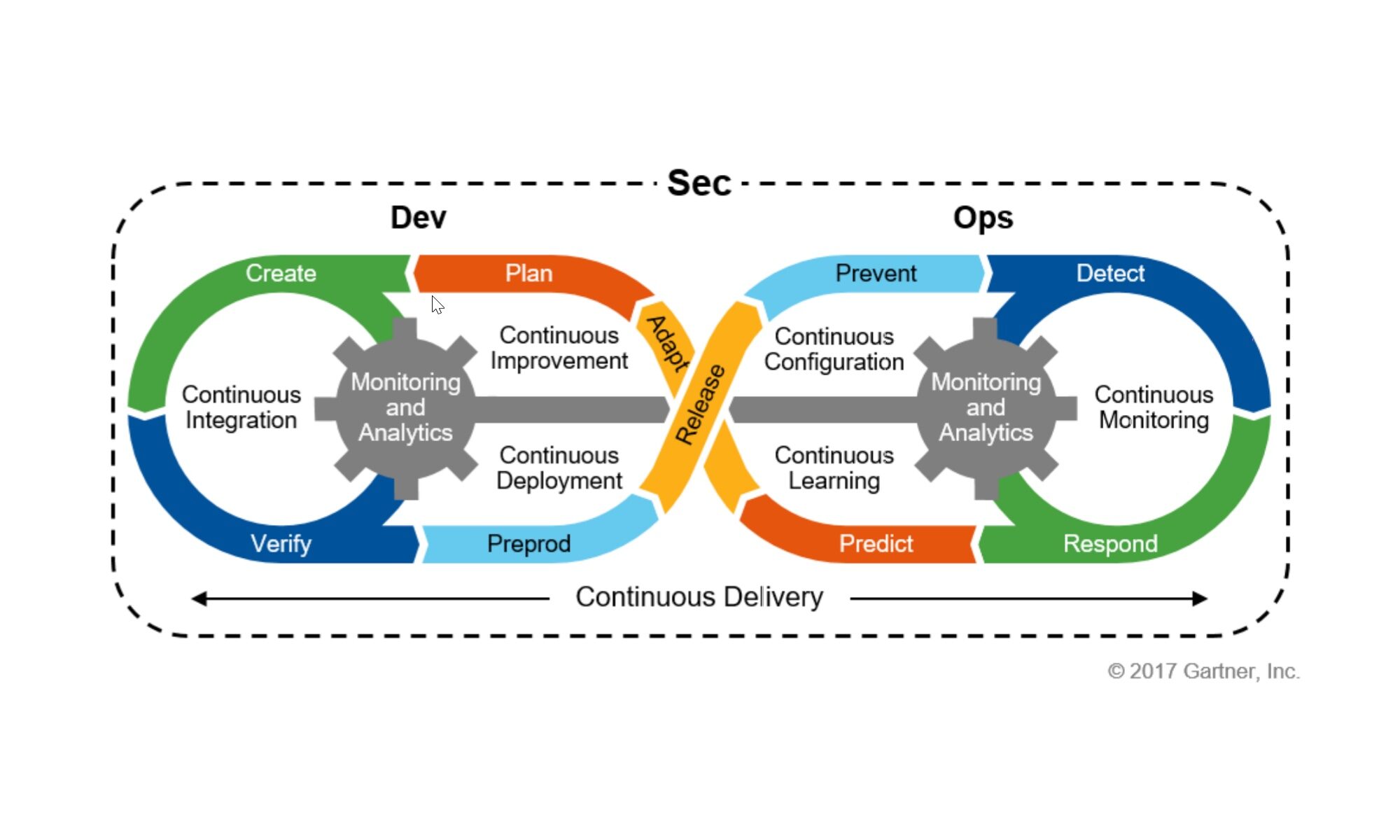
Depuis avril 2021, et la version 1.0 de Nautobot, cette célèbre Source de Vérité Open Source a parcouru beaucoup de chemin pour suivre les différentes évolutions de l’approche NetDevOps.
Beaucoup de travaux sont en préparation pour la version 2.0 attendue pour le deuxième trimestre 2023 :
- Recherches autour de l’interface utilisateur (UX research, UI technology research & prototyping, App. development pattern analysis, Foundational UI components, Core platform view overhaul)
- Améliorations du concept de jobs (Jobs termination, Database backends, Job logging, Job chaining, File output, Optional atomicity)
- Améliorations du modèle de données IPAM (Consolidation of models, Status vs type for prefixes, Hierarchy usability, Utilisation & allocation calculation refactoring, Extensible role model)
- Extensions de l’expérience développeur (Developer documentation, Model feature boilerplate, Exposed API & consolidation of imports)
- Améliorations diverses (Data model natural keys, Data model uniqueness constraints and indexing, Consolidation of location models, Filtering cleanup & dynamic field enhancements, Data import/export refactor with support for bulk updating, REST API versioning defaults, General code refactoring & changes to app. interfaces)