Dernière modification le 9 janvier 2022
A l’origine, le Web 3.0 a été nommé le Web sémantique par l’inventeur du World Wide Web, Tim Berners-Lee. Il visait à devenir un Internet plus autonome, intelligent et ouvert.
On peut ajouter que les données sont interconnectées de manière décentralisée, ce qui constitue un énorme pas en avant par rapport à notre génération actuelle d’Internet Web 2.0, où les données sont principalement stockées dans des référentiels centralisés.
Les utilisateurs et les machines peuvent interagir avec les données. Mais pour que cela se produise, les programmes doivent comprendre les informations à la fois conceptuellement et contextuellement. Dans cette optique, les deux technologies essentielles du Web 3.0 sont le Web sémantique et l’Intelligence Artificielle (IA).
Comme les réseaux Web 3.0 fonctionnent via des protocoles décentralisés – un des fondamentaux de la technologie blockchain et crypto-monnaie – nous voyons une forte convergence entre ces technologies.
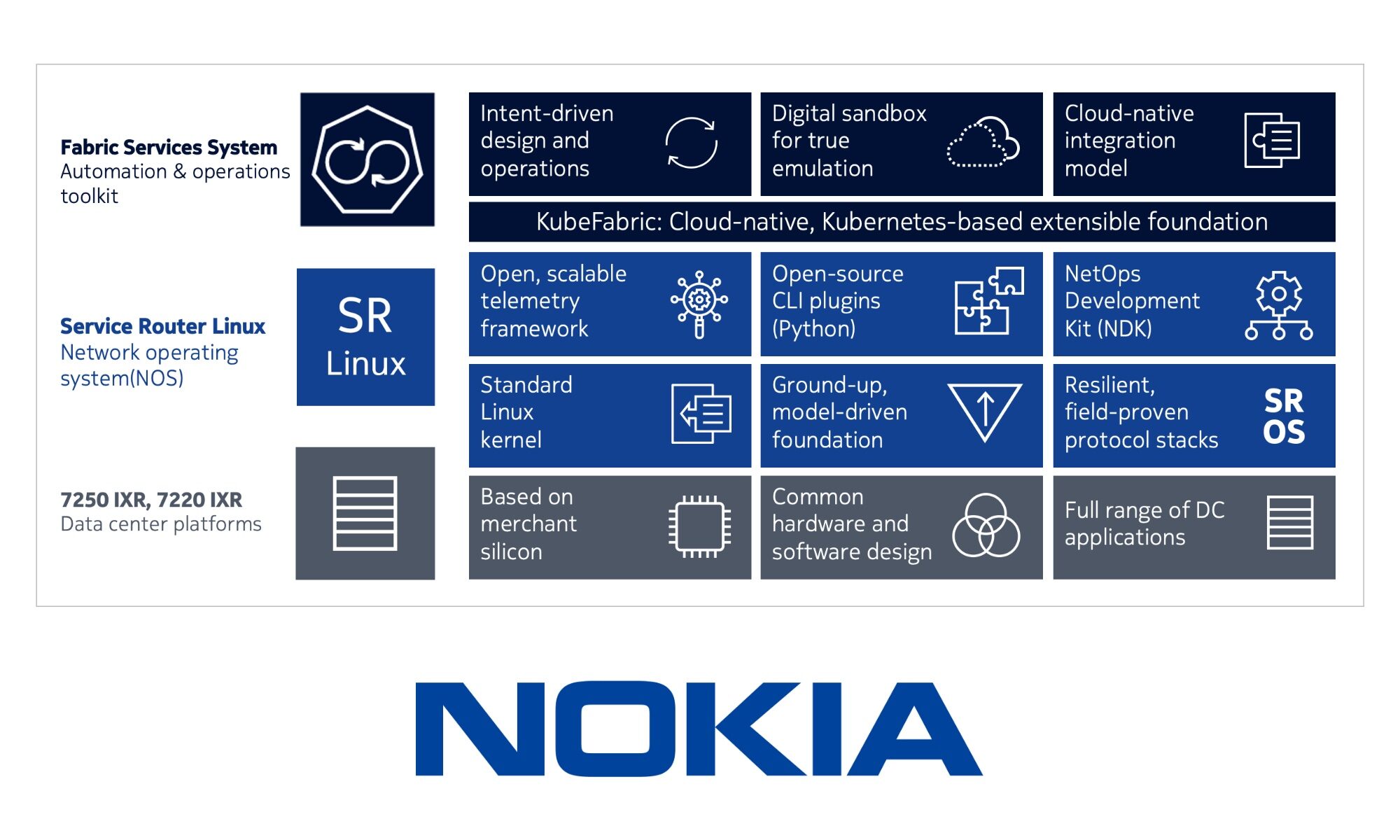
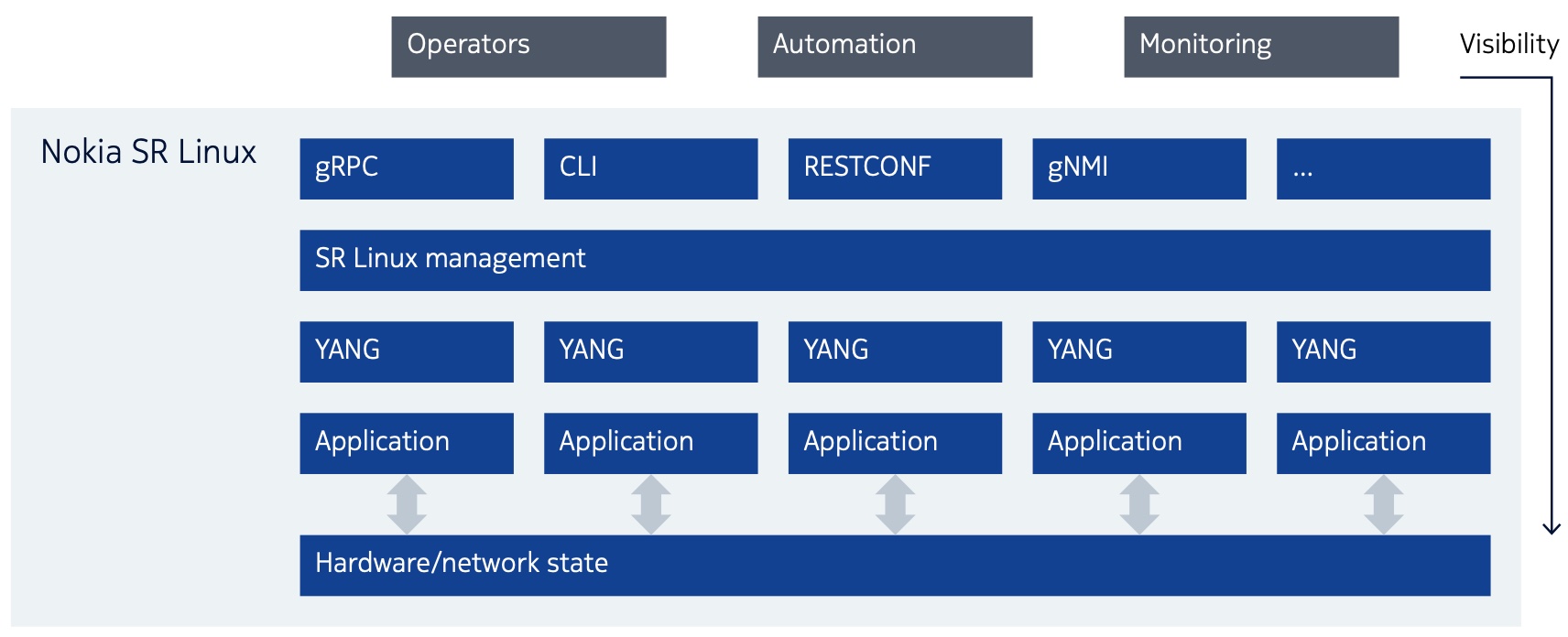
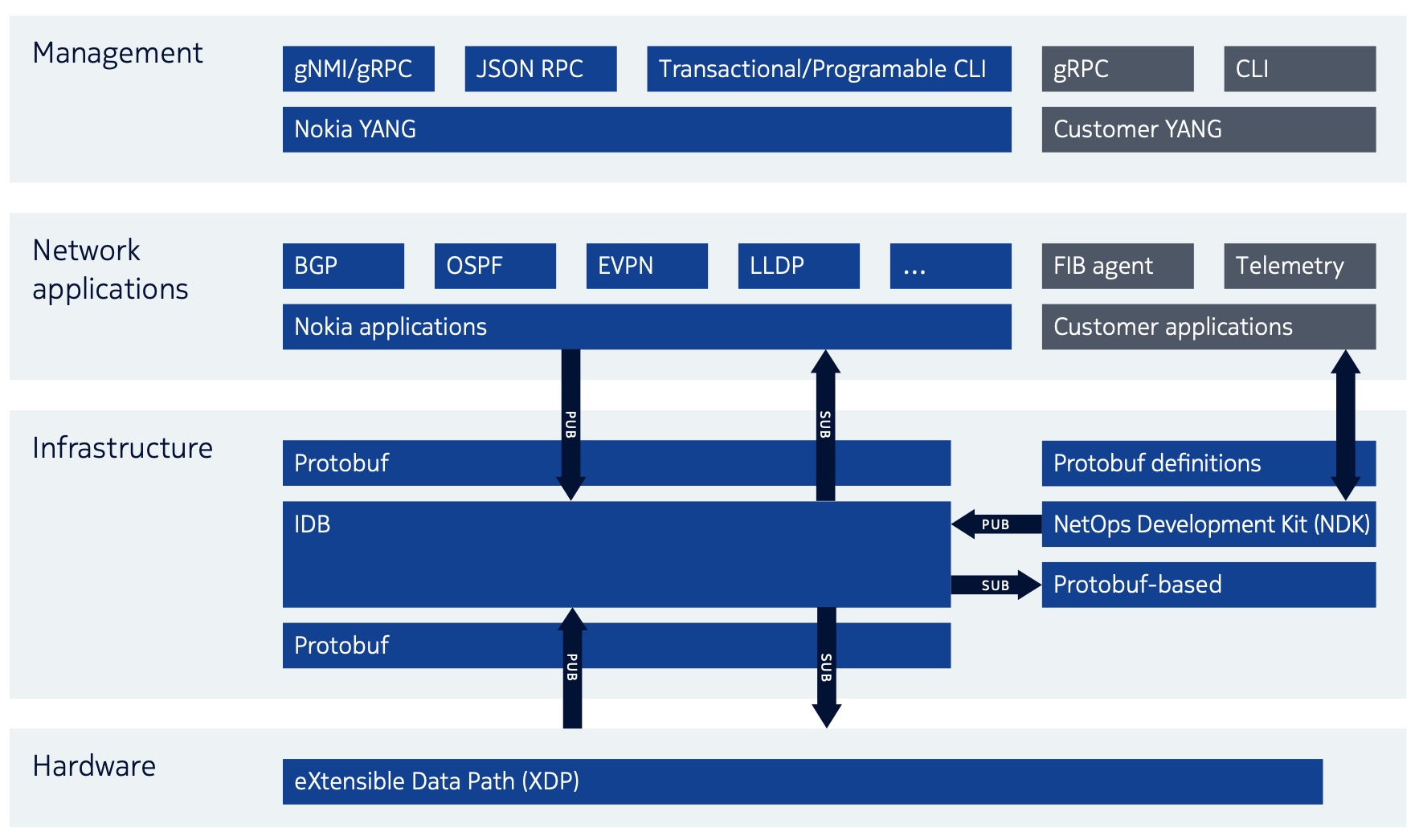
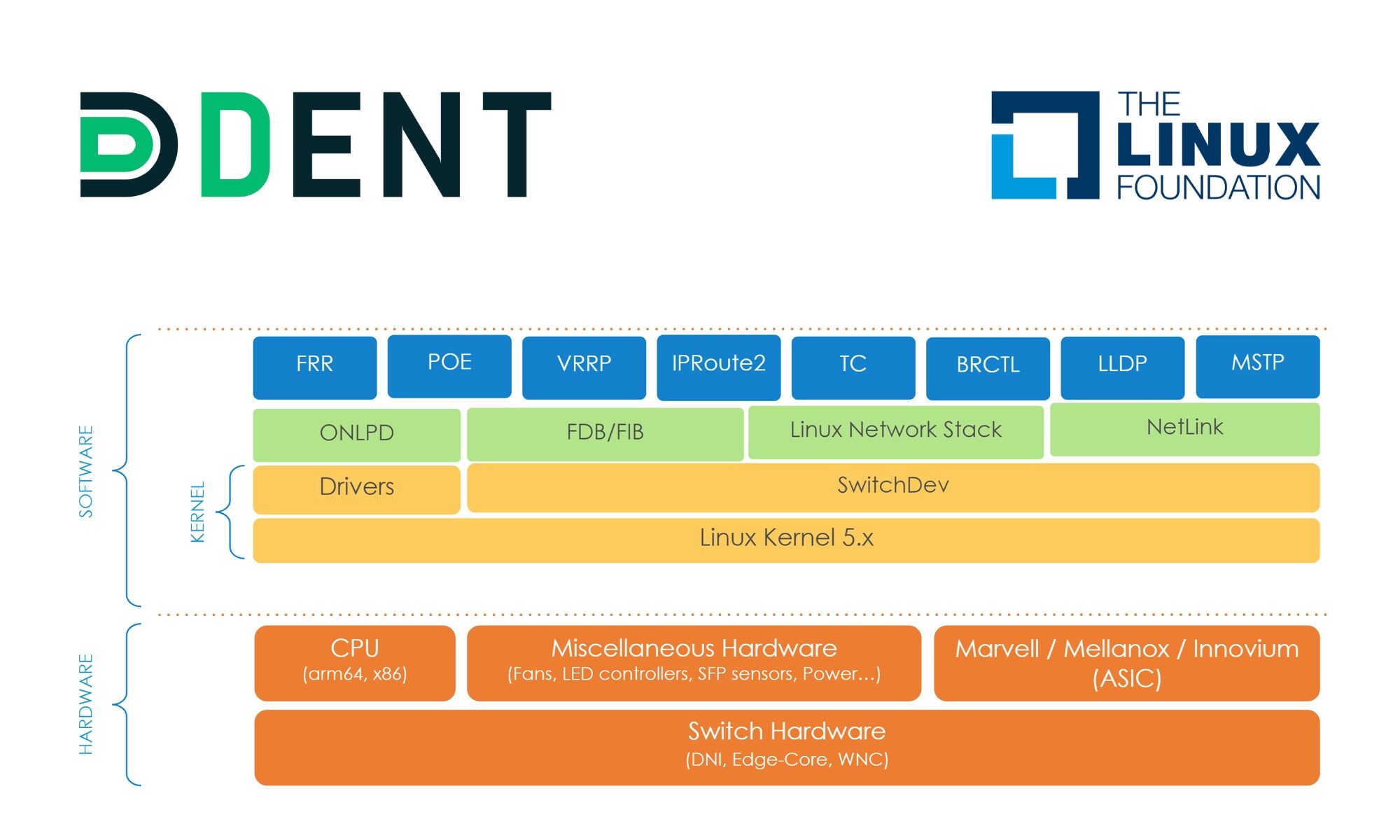
Toutes les personnes qui suivent les projets de la blockchain, savent que le Web 3.0 est déjà là au travers de nombreux projets qui couvrent plusieurs domaines actuellement entre les mains des GAFAM. Il en existe beaucoup, mais pour ne prendre que seulement deux d’entre eux, nous avons une illustration de la décentralisation de la fonction Cloud et de la fonction Recherche.
Continuer la lecture de « Le Web 3.0, technologie opérationnelle »