L’objectif de cet article est double : esquisser les grandes tendances NetDevOps observées en 2025 et montrer comment ces pratiques donnent corps à l’Intent‑Based Networking (IBN) défini par la RFC 9315. Aujourd’hui, pas de démonstration ni de recommandation sur une solution en particulier. L’idée est plutôt de donner au lecteur un fil rouge pour comprendre le « pourquoi » et le « comment » sans entrer dans les entrailles de la mise en place du NetDevOps. D’autres articles viendront mettre le focus sur une technologie ou une autre, avec des yeux d’experts qui travaillent dans le domaine pour de nombreux clients, sur des infrastructures qui vont du réseau universitaire aux plus gros datacenters d’Europe.
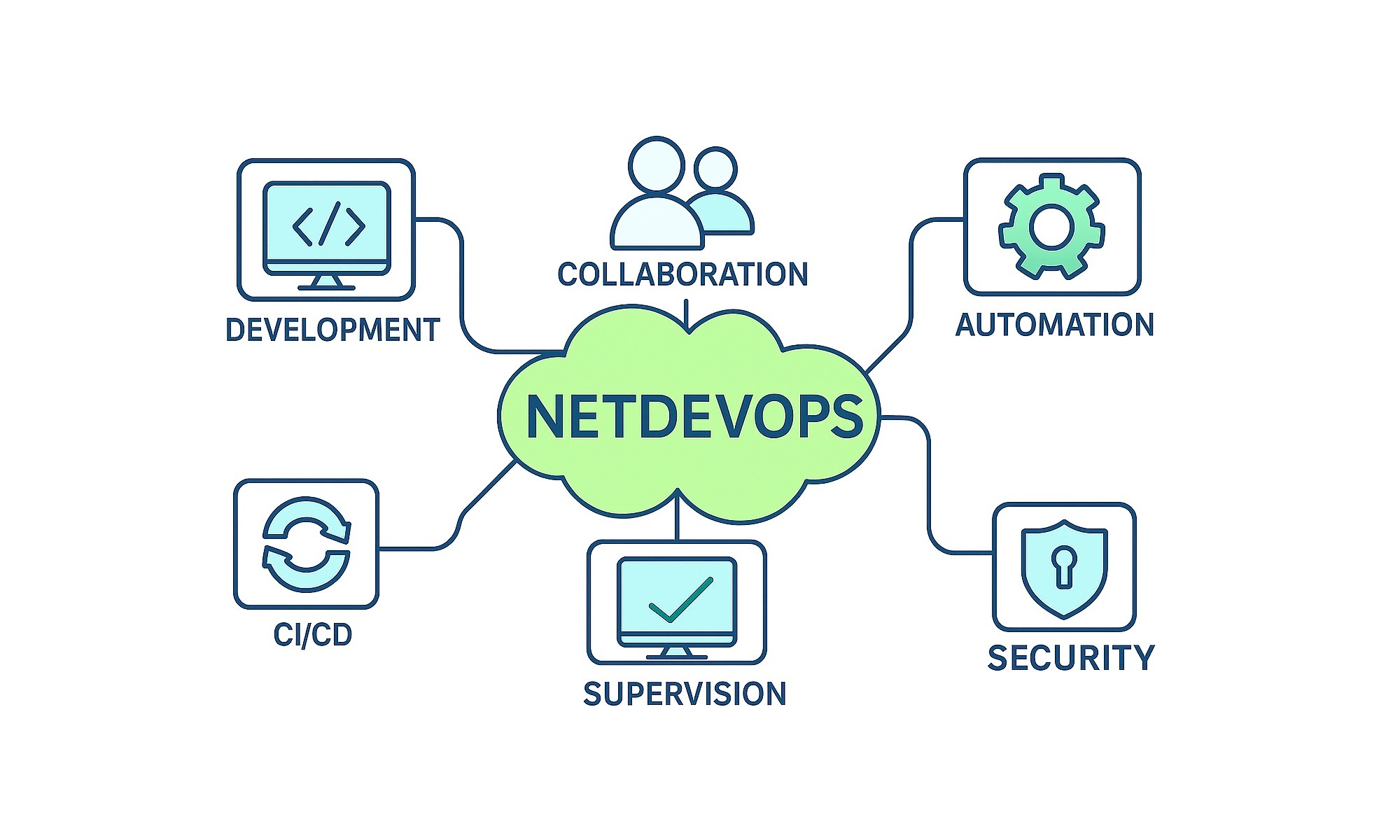
Les équipes réseau que nous accompagnons, avec l’équipe NXO NANO, ne considèrent plus l’automatisation comme un laboratoire. Les templates de configuration vivent désormais dans Git, enrichis par une source de vérité cohérente et validée ; chaque push déclenche une batterie de tests. Un sondage EMA paru début 2025 indique que les organisations prévoient d’augmenter d’environ 50 % leur taux d’automatisation réseau d’ici la fin de l’année – preuve que cette démarche est désormais perçue comme aussi stratégique que la haute disponibilité applicative1.
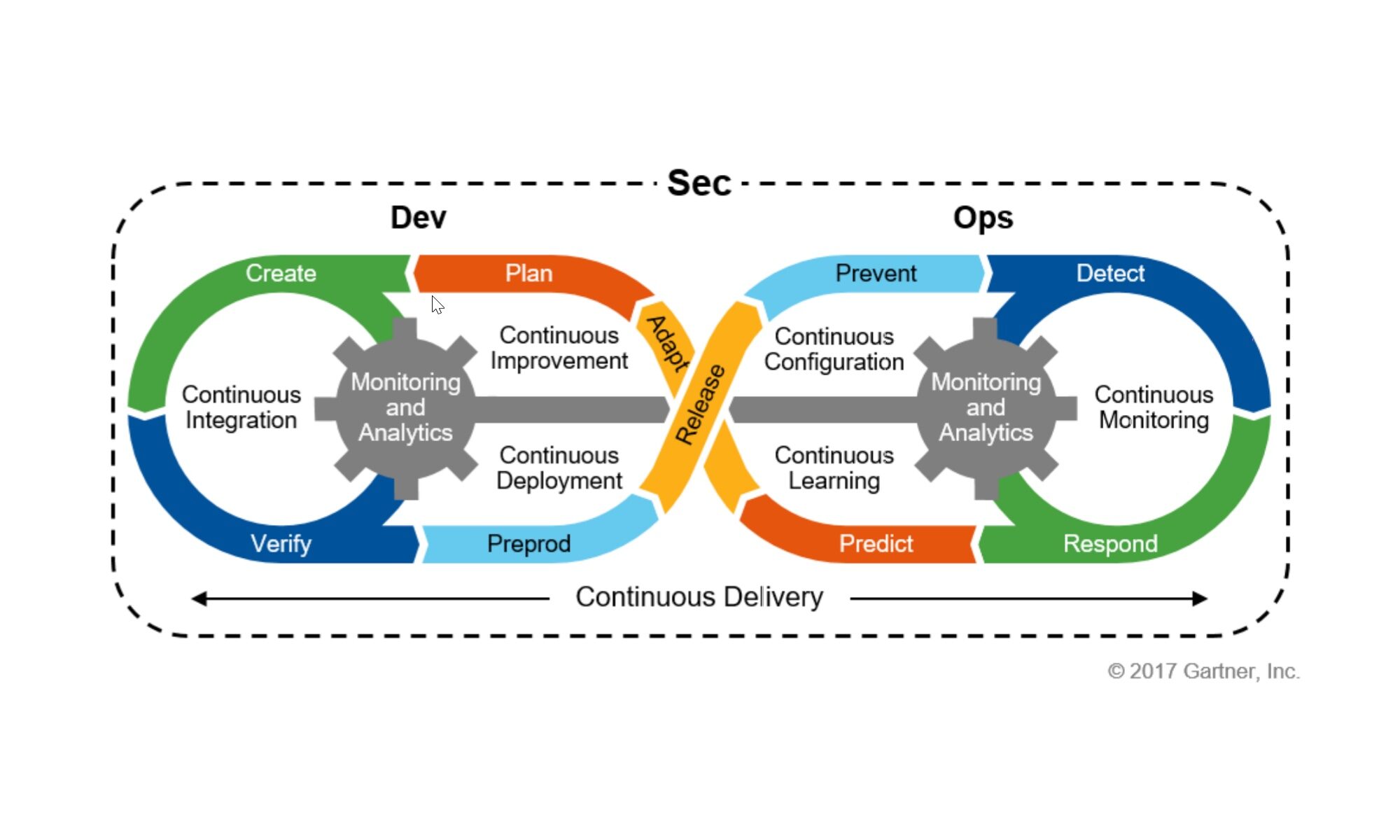
Publiée fin 2022, la RFC 9315 a posé le vocabulaire qui manquait. L’intent y est défini comme l’objectif déclaré du réseau, indépendamment de la façon d’y parvenir. Deux fonctions l’encadrent : fulfilment (la réalisation), et assurance (le contrôle continu). Tout tourne autour de deux boucles : l’externe, où le besoin métier fait évoluer l’intent, et l’interne, où la plateforme compare en permanence l’état réel à l’état voulu et agit en conséquence2.
Continuer la lecture de « NetDevOps 2025 : de la norme RFC 9315 à l’implémentation »