

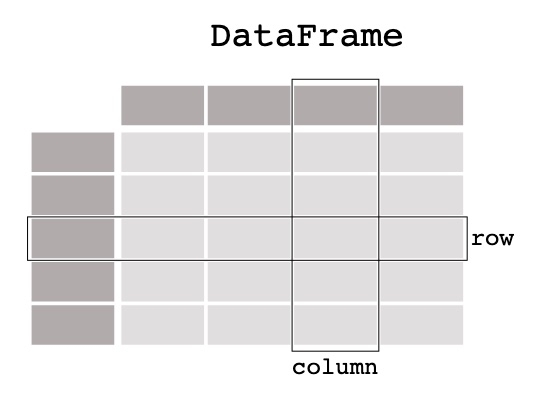
Pandas est un outil d’analyse et de manipulation de données Open Source, écrit en Python, rapide, puissant, flexible et facile à utiliser. Lorsqu’on travaille avec des données tabulaires, telles que des données stockées dans des feuilles de calcul ou des bases de données, pandas est l’outil adapté. Pandas aide à explorer, nettoyer et traiter les données. Dans pandas, une table de données s’appelle un DataFrame.
Pandas prend en charge, nativement, l’intégration de nombreux formats de fichiers ou sources de données (csv, excel, sql, json, parquet,…). L’importation de données à partir de chacune de ces sources de données est réalisée par une fonction avec le préfixe read_*. De la même manière, les méthodes to_* sont utilisées pour stocker des données.

Que ce soit pour sélectionner ou filtrer des lignes et/ou des colonnes spécifiques, ou que ce soit pour filtrer les données sur une condition, des méthodes pour découper, sélectionner et extraire les données nécessaires sont disponibles dans pandas.
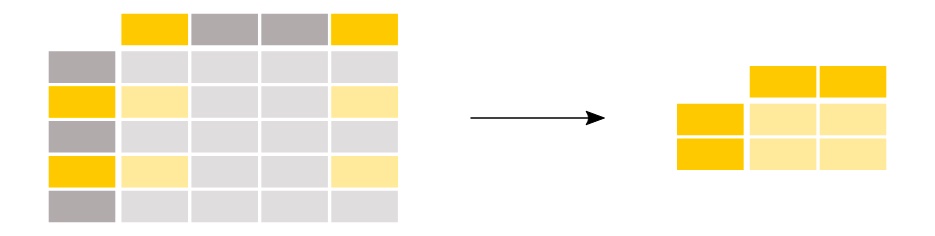
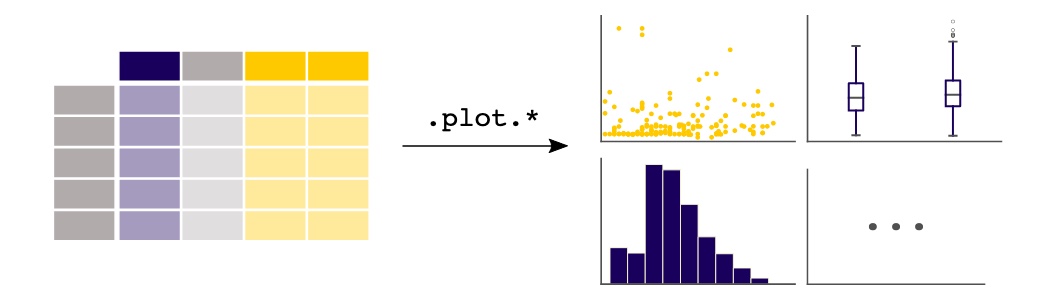
Pandas permet de tracer les données prêtes à l’emploi, en utilisant la puissance de Matplotlib. On peut choisir le type de tracé (scatter, bar, boxplot,…) correspondant aux données.
Il n’est pas nécessaire de boucler sur toutes les lignes du tableau de données pour effectuer des calculs. Les manipulations de données sur une colonne fonctionnent élément par élément. L’ajout d’une colonne à un DataFrame est simple.

Les statistiques de base (moyenne, médiane, min, max, …) sont facilement calculables. Ces calculs peuvent être appliqués à l’ensemble du jeu de données, à une fenêtre glissante des données ou à des données regroupées par catégories. Cette dernière est également connue sous le nom d’approche fractionner-appliquer-combiner.
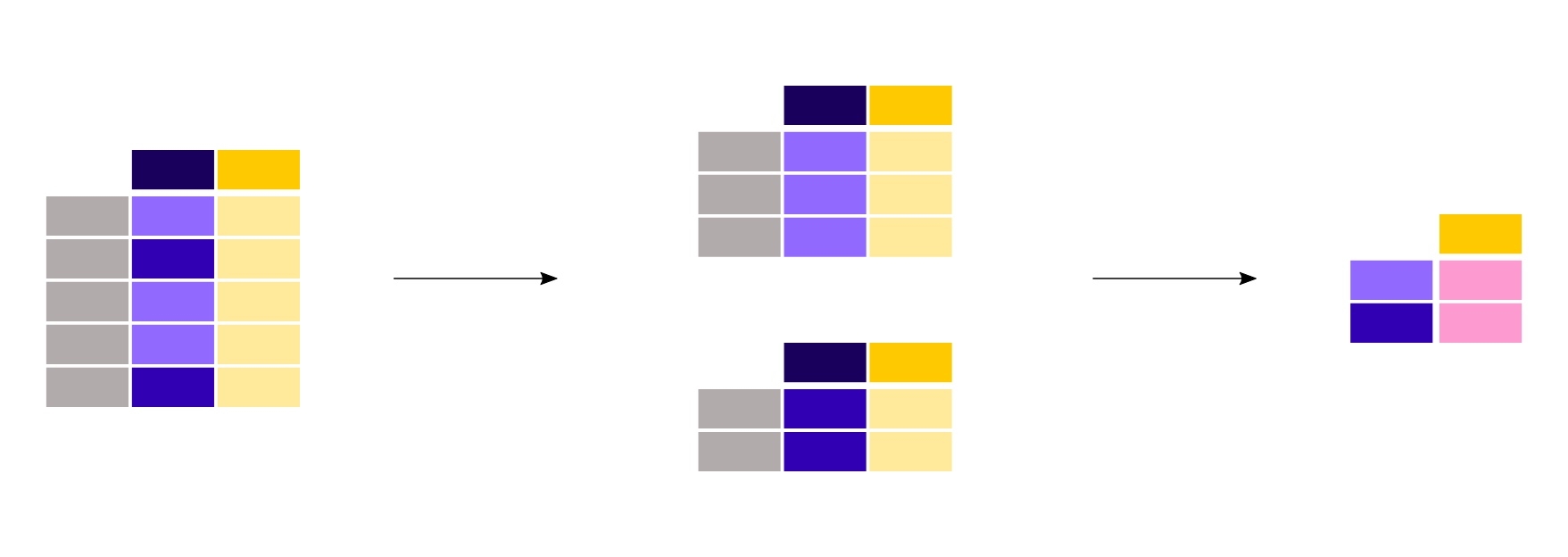
Il existe plusieurs façons de modifier la structure d’une table de données. On peut utiliser melt() pour passer la table de données du format wide au format long/tidy ou pivot() pour passer du format long au format wide. Avec les agrégations intégrées, un tableau croisé dynamique est créé avec une seule commande.

Plusieurs tables peuvent être concaténées à la fois par colonne et par ligne, car des opérations join/merge de type base de données sont fournies pour combiner plusieurs tables de données.
Python pandas prend en charge les séries chronologiques (time series) et dispose d’un ensemble complet d’outils pour travailler avec des dates, des heures et des données indexées dans le temps. Les ensembles de données ne contiennent pas que des éléments numériques. Pandas fournit un large éventail de fonctions pour nettoyer les données textuelles et en extraire des informations utiles.
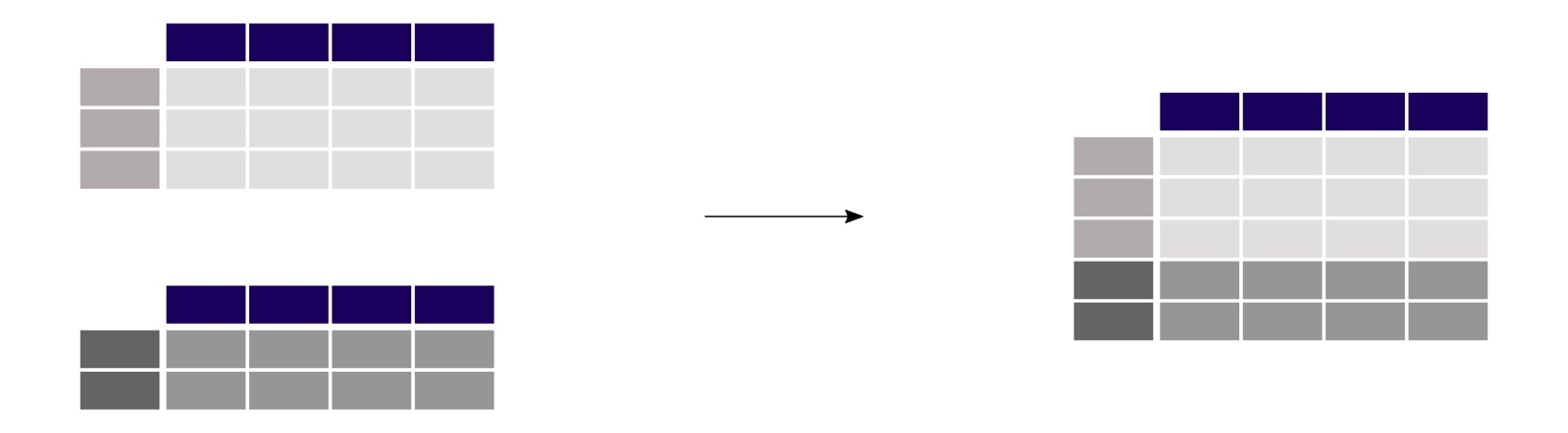
Les habitudes ayant la vie dure, il est encore fréquent qu’une équipe NetDevOps reçoive des informations réseau dans des fichiers Excel ou CSV. Pandas permet de manipuler directement toutes ces données sans passer par des étapes lourdes pouvant entrainer une distorsion des données. Une illustration très simple permet de comprendre les bases de la manipulation d’un DataFrame avec pandas.
#!/usr/bin/env python
from pandas import DataFrame
df = DataFrame(
[
["10.10.10.1", "admin", "admin", "Switch"],
["10.10.10.2", "admin", "admin", "Switch"],
["10.10.10.3", "admin", "admin", "Switch"],
["10.10.10.4", "admin", "admin", "Switch"],
["10.10.10.5", "admin", "admin", "Router"]
],
index=["spine1", "spine2", "leaf1", "leaf2", "gateway"],
columns=["IP@", "Username", "Password", "Type"]
)
tests = [df, df.head(1), df.tail(1), df.loc["spine1"]]
def line():
return "\033[94m" + "=" * 50 + "\033[0m"
print(line())
for test in tests:
print(test)
print(line())
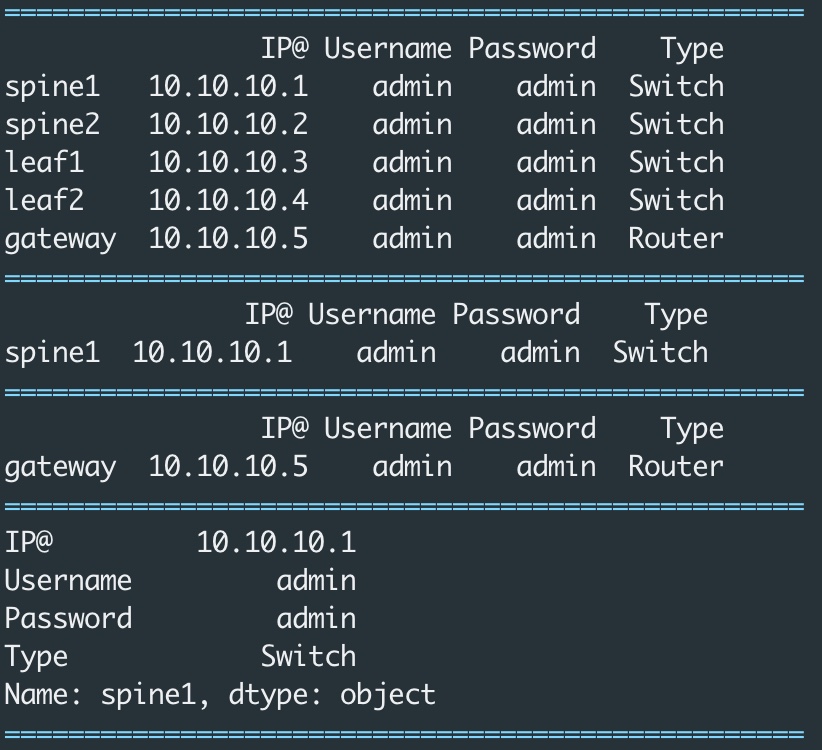
Il est aisé d’extraire des informations du DataFrame et de formater le résultat sous une forme utile pour la suite.
#!/usr/bin/env python
from pandas import DataFrame
df = DataFrame(
[
["10.10.10.1", "admin", "admin", "Switch"],
["10.10.10.2", "admin", "admin", "Switch"],
["10.10.10.3", "admin", "admin", "Switch"],
["10.10.10.4", "admin", "admin", "Switch"],
["10.10.10.5", "admin", "admin", "Router"]
],
index=["spine1", "spine2", "leaf1", "leaf2", "gateway"],
columns=["IP@", "Username", "Password", "Type"]
)
def line():
return "\033[94m" + "=" * 56 + "\033[0m"
print(line())
print(df["IP@"].loc[df["Type"] == "Router"].values)
print(line())
print(df["IP@"].loc[df["Type"] == "Switch"].to_list())
print(line())

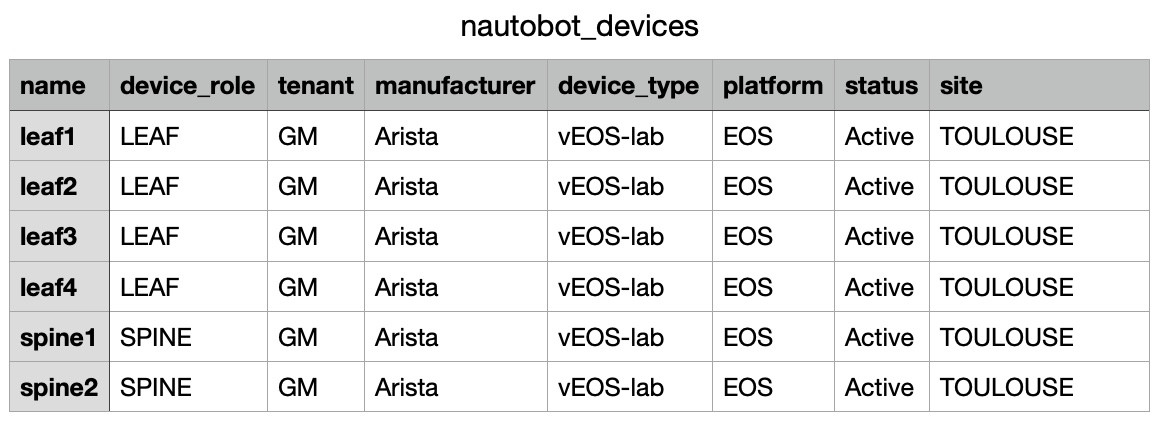
Si on dispose d’un fichier Excel du type ci-dessous, il est possible de l’importer en tant que DataFrame pandas pour le manipuler. Pour ce faire, il convient d’installer une dépendance supplémentaire : openpyxl.
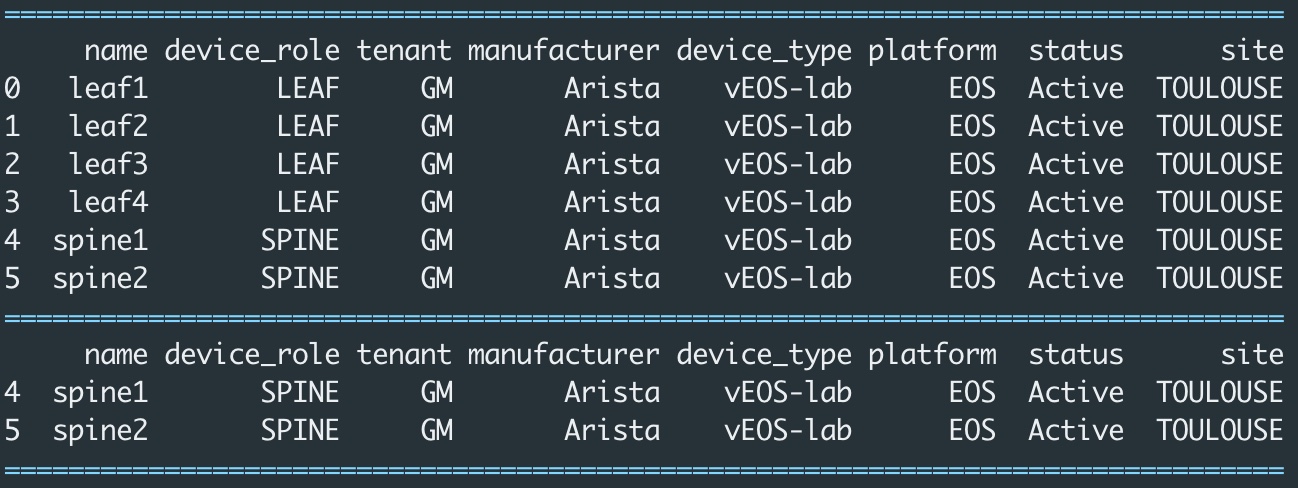
#!/usr/bin/env python
from pandas import DataFrame, ExcelFile, read_excel
def line():
return "\033[94m" + "=" * 80 + "\033[0m"
print(line())
with ExcelFile("nautobot_devices.xlsx") as input_file:
my_df = read_excel(input_file, header=[1])
print(my_df)
print(line())
print(my_df.loc[my_df["device_role"] == "SPINE"])
print(line())
Les possibilités de manipulations de données sont très variées. Pour avoir une vision plus exhaustive des possibilités, la documentation proposée pour pandas est très complète.