
Dernière modification le 11 janvier 2020
Le mouvement DevOps a pris naissance dans le monde de l’édition logicielle. NetDevOps, parfois nommé NetOps, est une transposition de ce modèle dans le monde du réseau. Le rapprochement entre les équipes de développement et d’exploitation, ayant des objectifs différents pour ne pas dire antinomiques, au sein d’une même équipe est un concept qui se marie bien avec le modèle Agile et traduit des éléments qui y sont abordés. Ce mouvement met en valeur les notions d’Intégration Continue ou « Continuous Integration » (CI), de Livraison Continue ou « Continuous Delivery » (CD) et de Déploiement Continu ou « Continuous Deployment » (CD). L’Intégration Continue consiste à mettre en place une plateforme sur laquelle les modifications sont poussées et soumises à des jeux de tests unitaires afin d’être packagées dans un référentiel central utilisé pour le déploiement sur l’ensemble des environnements. Cette plateforme offre l’avantage de proposer un contexte standardisé et beaucoup plus neutre que les postes de travail personnalisés de chaque développeur sur lesquels il pourrait exister des contournements des règles de base de qualité et avec lesquels on ne pourrait pas garantir la répétabilité des processus. Le principe de l’Intégration continue induit que la configuration est, à tout moment, potentiellement livrable, mais elle ne peut pas passer en production sans l’aval des équipes opérationnelles. La différence entre la Livraison Continue et le Déploiement Continu se situe uniquement sur le fait qu’après la Livraison une approbation manuelle est nécessaire pour passer en Déploiement, alors que lorsqu’on parle de Déploiement Continu c’est que la mise en production est automatisée. Dans les deux cas, l’objectif est la mise en production sans incident ni régression. C’est à ce stade que les tests d’acceptation sont nécessaires, avant mise en production, afin de garantir le bon fonctionnement de l’ensemble d’un point de vu utilisateur final.
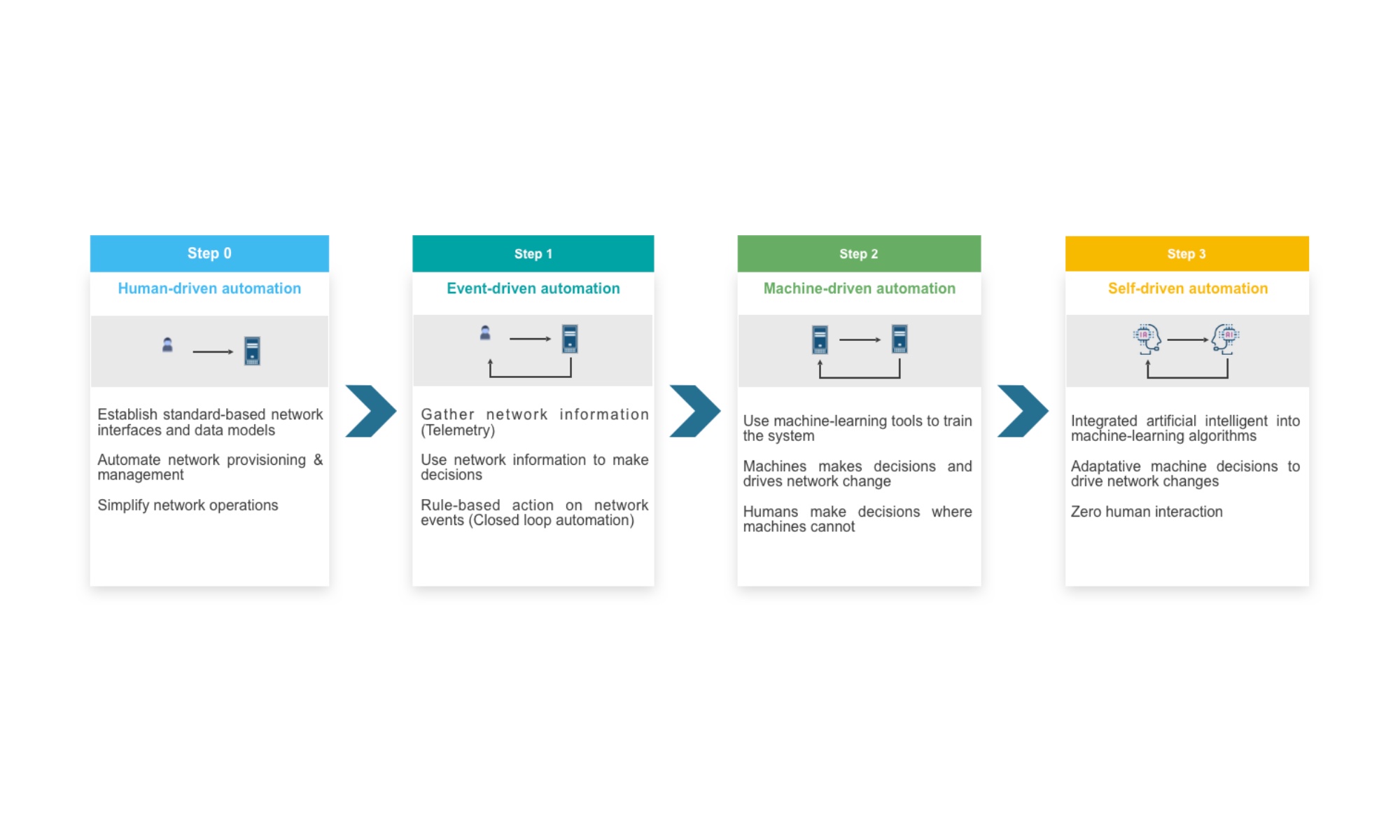
La méthode traditionnelle utilisée pour manipuler les réseaux consiste à se connecter manuellement avec un compte et un mot de passe sur les équipements et entrer des commandes ou copier/coller des commandes préparées dans un éditeur de texte. Certains constructeurs possèdent des processus plus ou moins évolués pour revenir en arrière en cas de problème, mais la moindre petite erreur peut engendrer un dysfonctionnement sur l’ensemble du réseau. Améliorer les méthodologies a pour objectifs d’améliorer la disponibilité et la sécurité des réseaux, mais aussi de mieux répondre aux méthodes inspirées de l’approche Agile maintenant utilisées dans le monde des réseaux. L’automatisation, appliquée au domaine du réseau, peut se décliner en quatre niveaux progressifs d’implémentation.
« Human-driven automation » est le plus connu. Des scripts sont réalisés et un environnement d’automatisation est mis en place pour permettre de provisionner des équipements depuis leur première mise en route. Au démarrage, cette fonction s’appelle ZTP (Zero Touch Provisioning) ou ZTD (Zero Touch Deployment). L’idée consiste à permettre la mise à jour de l’équipement et la mise en place d’une configuration minimum sans avoir à se connecter sur l’équipement. Une fois la configuration minimum active (généralement au moins le réseau d’administration Out-of-Band), des successions de scripts et de tests vont être lancés progressivement et manuellement pour aller vers le système cible. Durant les phases d’exploitation, les équipements peuvent être reconfigurés mais aussi interrogés à des fins de tests. Le langage Python, et toutes les librairies adaptées pouvant être choisies, est un bon point de départ pour implémenter ce niveau d’automatisation.
« Event-driven automation » sous-entend qu’on utilise aussi le premier niveau d’automatisation, mais rajoute le fait de réagir à des évènements réseau. Ces évènements peuvent être tirés des messages syslog qui sont remontés vers le serveur d’automatisation pour analyse. Des réactions sont armées pour avertir des administrateurs ou pour lancer automatiquement des actions binaires en réponse à l’évènement produit. On commence à introduire la notion de télémétrie qui peut également servir pour analyser des évènements réseau et déclencher des réactions par webhooks.
Lorsque des réactions plus compliquées doivent être mise en place, c’est-à-dire des réactions qui peuvent être déduites de situations complexes, il est nécessaire de faire appel à l’intelligence artificielle qui se divise en deux grande catégories. L’AGI (Artificial General Intelligence) consiste à vouloir reproduire tout ce qu’un être humain est capable de faire, alors que l’ANI (Artificial Narrow Intelligence) consiste à réaliser des actions élémentaires. Dans cette dernière catégorie, le « Supervised Learning », appelé Machine Learning, permet de faire correspondre un output B à un Input A. Ce modèle fonctionne bien pour les apprentissages de concepts simples (pensée ≤ 1 seconde) avec beaucoup de données disponibles. Lorsqu’on veut faire correspondre à un Output B un Input A multicritères, le Deep Learning ou Neural Network est le plus adapté. Conjointement à ces concepts, la Data Science, ou Big Data qui consiste à extraire la connaissance des données, est un élément constituant de l’intelligence artificielle. Gartner estime qu’en 2022 40% des grande entreprises combineront le Big Data et les fonctionnalités de Machine Learning pour supporter et remplacer partiellement le monitoring, le centre de support et les processus d’automatisation, alors que ça ne représente que 5% aujourd’hui. McKinsey Global Institute estime la création de valeur de l’IA à 13 Milliard de Milliards de dollars vers 2030. Le « Machine-driven automation » vient se greffer sur le modèle « Event-driven automation » pour permettre des réactions automatiques plus élaborées face à des situations plus complexes. Lorsque l’être humain n’aura plus à supplanter la machine dans certaines phases de décision, le niveau « Self-driving automation » aura été atteint.