

Dernière modification le 11 janvier 2020
Docker est un système de gestion de conteneurs incontournable dans le domaine du NetDevOps. La notion de conteneur est utilisée pour faire tourner une application de manière isolée et légère sur l’hôte sur lequel Docker est installé. L’accès aux services internes au conteneur se fait par une redirection de ports sur l’hôte qui fait tourner Docker.
La première préoccupation qui apparaît, avec la notion de conteneur, est la persistance des données. En effet, lorsque le conteneur est détruit, les données sont détruites avec lui. Si ce comportement peut être voulu pour repartir facilement d’une base vierge, il est des cas dans lesquels on veut garder l’historique des données. Pour palier à cela, il est facile d’utiliser la notion de volume, en les stockant dans un répertoire spécifique du serveur hôte Docker plutôt que dans le système de fichiers par défaut du conteneur. Ce stockage externe, appelé volume de données, permet de rendre les données indépendantes de la vie du conteneur, soit en le créant de toute pièce, soit en faisant une correspondance entre un répertoire source existant sur l’hôte et le répertoire destination dans le conteneur. Le volume permet également de partager ces données entre plusieurs conteneurs sur un même hôte.
Pour faire tourner la totalité d’une application, il n’est pas rare d’utiliser plusieurs conteneurs, chacun spécialisé dans une tâche particulière (par exemple un conteneur pour le serveur web et un conteneur pour la base de données). Pour simplifier la gestion de cet ensemble de conteneurs, il existe l’outil docker-compose. Il permet de définir des applications multi-conteneurs, appelées Stacks, et de les exécuter soit sur un seul nœud Docker, soit dans un cluster. L’outil fournit des programmes en ligne de commande permettant de gérer le cycle de vie complet des applications.
La mise en place simple d’un cluster Docker fait appel au logiciel Swarm, maintenant intégré directement avec Docker. Il consolide des hôtes Docker dans un cluster et permet la gestion centrale de celui-ci ainsi que l’orchestration des conteneurs.
Un hôte Docker peut prendre le rôle de Manager ou de Worker ou même des deux. Le Swarm Manager est responsable de la gestion du cluster et de la répartition des tâches, alors que les Swarm Workers prennent en charge l’exécution des tâches. La règle de haute disponibilité à appliquer est qu’un cluster Swarm de (N) Managers tolère une panne de [(N – 1) / 2] Managers. Quoi qu’il en soit Docker recommande d’utiliser un maximum de 7 Managers.
Les applications de conteneurs sont distribuées sur un certain nombre de nœuds Docker en tant que Services. Chaque service représente un ensemble de tâches individuelles, dont chacune est traitée dans son propre conteneur sur l’un des nœuds du cluster. Docker Swarm supporte deux modes dans lesquels les services Swarm sont définis :
- Services répliqués : un service répliqué est une tâche qui s’exécute dans un nombre de répliques défini par l’utilisateur. Chaque réplique est une instance du conteneur Docker défini dans le service.
- Services globaux : lorsqu’un service s’exécute en mode global, chaque nœud disponible dans le cluster démarre une tâche pour le service correspondant. Lorsqu’un nouveau nœud est ajouté au cluster, le gestionnaire Swarm lui assigne immédiatement une tâche pour le service global.
Pour traiter la persistance des données dans un cluster, il convient d’utiliser un système de stockage centralisé ou un outil de stockage réseau. Les deux outils les plus connus pour faire du stockage réseau entre des hôtes sont Ceph et Gluster, le plus simple étant le dernier. En utilisant ces outils, on peut définir un espace de stockage commun à tous les hôtes sur lesquels des conteneurs sont amenés à se déplacer et/ou à partager des données entre eux.
L’autorisation de la communication entre les conteneurs nécessite l’usage de la notion de réseau, le plus souvent bridgé.
Pour administrer un nœud Docker ou un cluster Docker Swarm, l’outil Portainer, lui même sous forme de conteneur, est bien approprié.
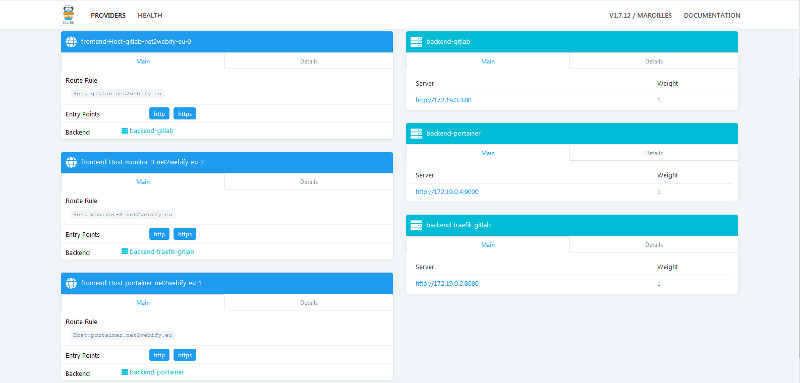
Il est fréquent que les conteneurs accédés depuis l’extérieur proposent des services web. Pour sécuriser l’accès web en SSL, l’usage d’un reverse proxy spécialisé est préconisé. J’entends par « spécialisé », le fait qu’il puisse s’adapter tout seul au nombre de réplicas qui tournent tout en gérant la répartition de charge. L’outil le plus adapté pour cette tâche est Traefik. Il va automatiser les règles de routage des sous-domaines vers les bons conteneurs en se connectant à l’API de Docker. Ainsi, chaque nouveau conteneur pourra être configuré avec un sous-domaine et obtenir un certificat HTTPS créé par Let’s encrypt pour chaque sous-domaine. C’est un outil qui tourne, lui aussi, sous la forme d’un conteneur Docker.
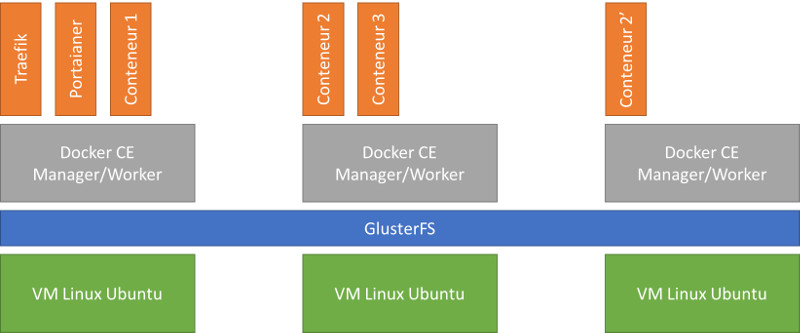
Mon approche préférée pour mettre en place un cluster Swarm, est d’abord de mettre en place une solution de virtualisation à cheval sur au moins deux nœuds bare metal et ensuite de déployer des hôtes Docker sous la forme de VMs. Le résultat est un ensemble fortement disponible et moins coûteux que d’utiliser des serveurs physiques pour les hôtes Docker.
Un cheat sheet Docker est toujours aussi pratique pour servir de fiches de rappel.