Dernière modification le 16 avril 2022
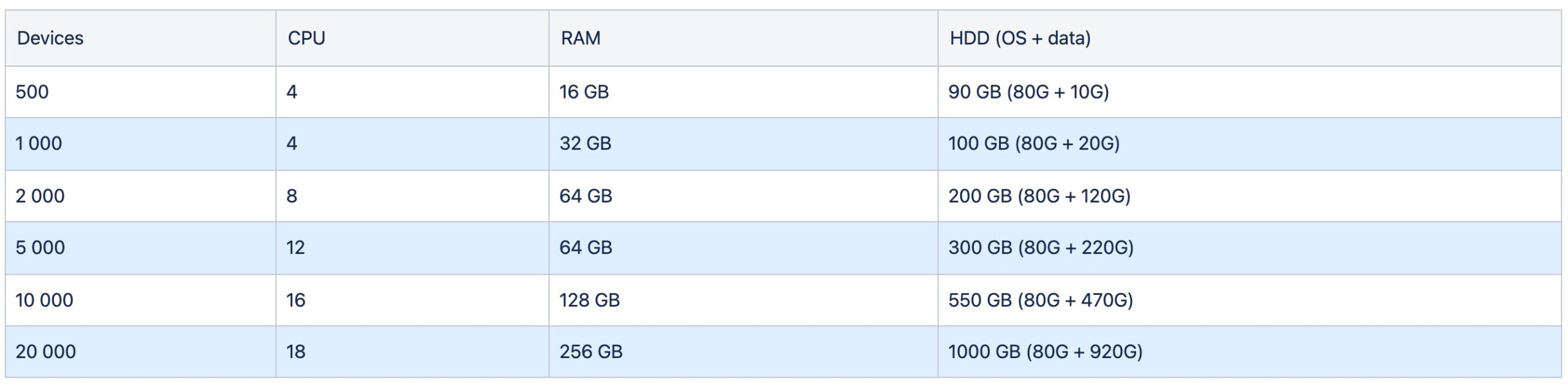
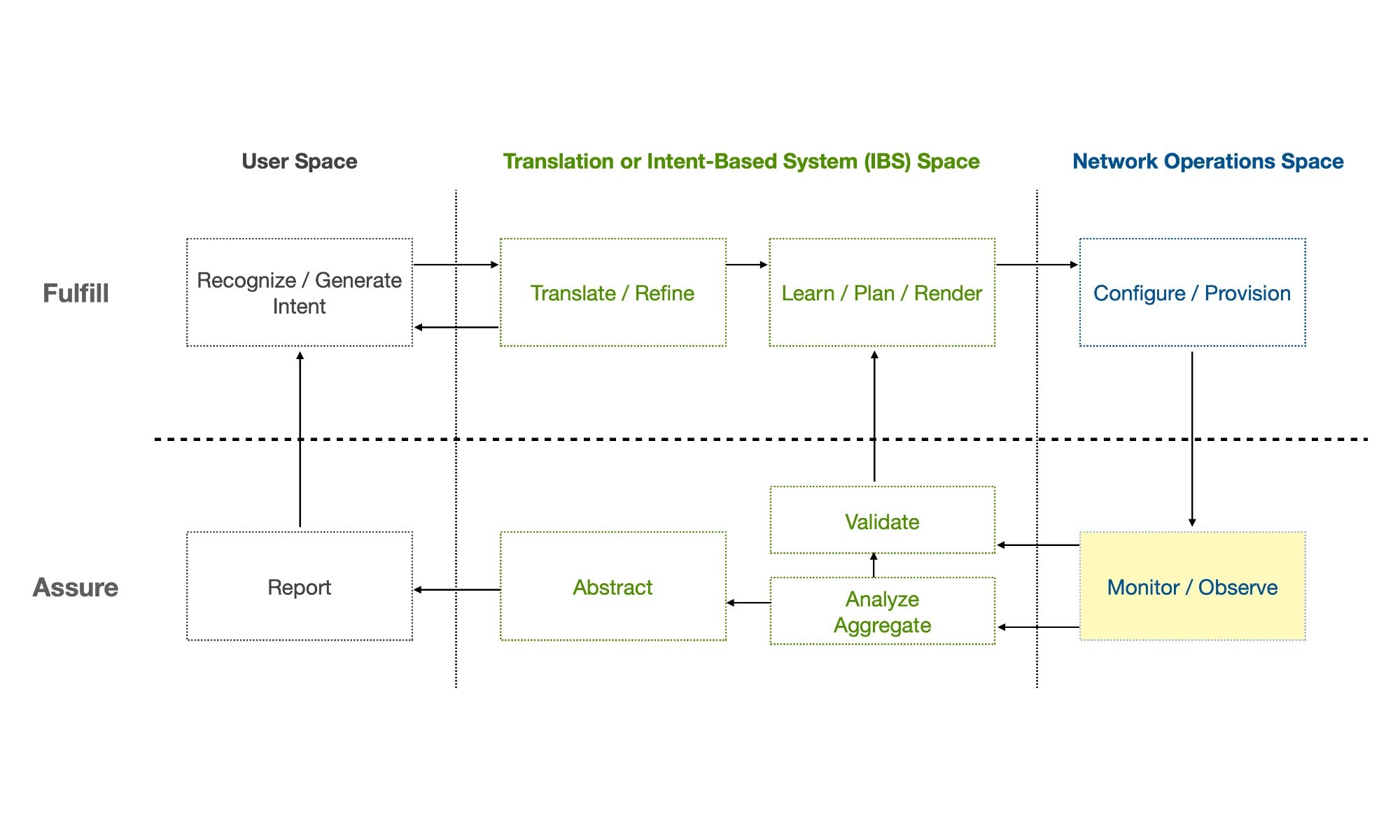
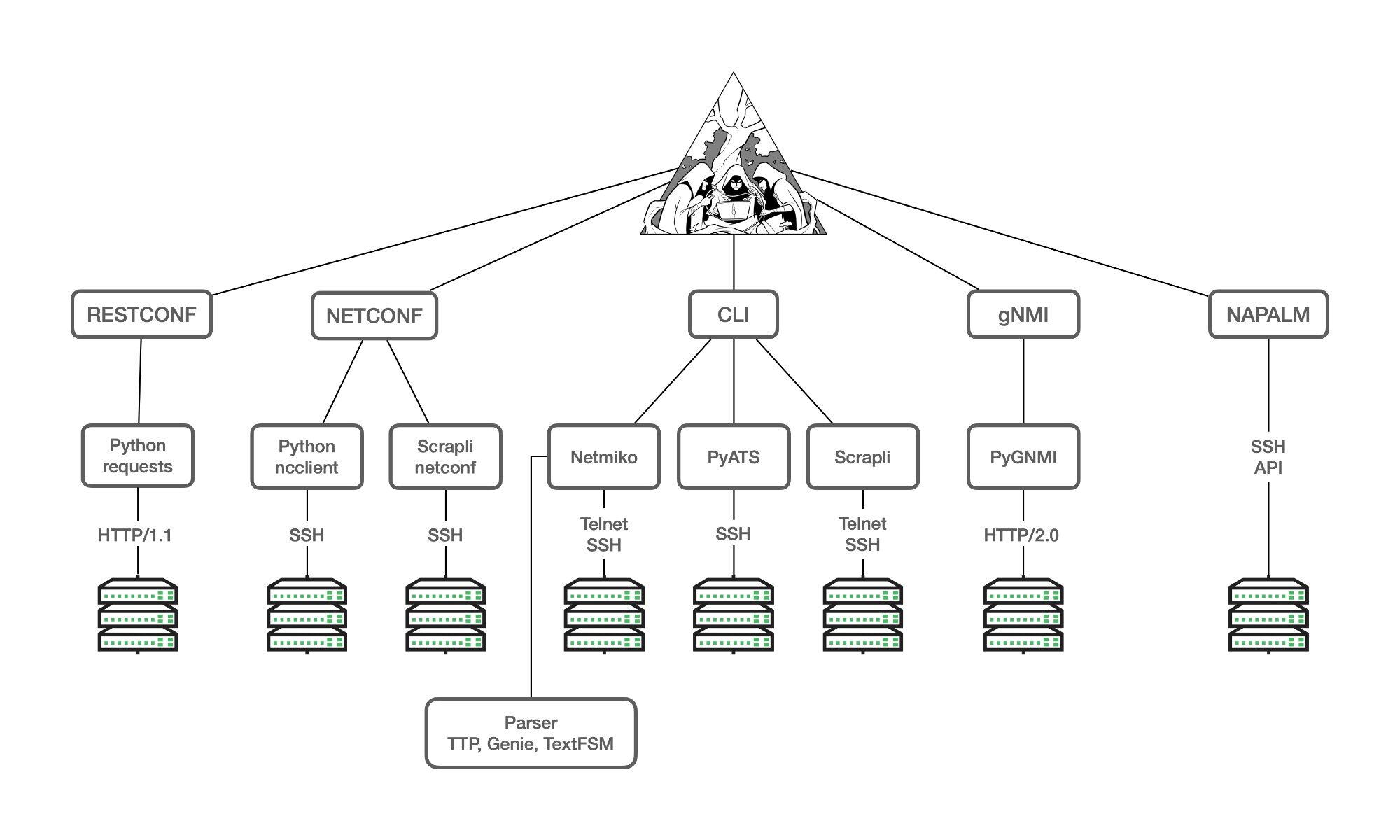
Dans la boucle interne de l’Intent-Based Networking, il y a la partie « Intent Fulfillment » qui consiste à partir d’une Source de Vérité unique pour générer des configurations en direction des équipements (directement vers les équipements ou en passant pas une station de management) à l’aide d’un ensemble de programme et la partie « Intent Assurance » qui comprend, entre autre, le « Monitoring ».
Que ce soit dans ou en dehors de la démarche NetDevOps , le chapitre « Monitoring », qui comprend l’observabilité du réseau, est souvent mal compris et mal pris en compte.
Lorsque le sujet de la visibilité du réseau est abordé, la plupart des professionnels pensent à la surveillance du réseau en terme de monitoring traduit par « surveillance ». Les outils de monitoring fournissent une vue centralisée de la santé opérationnelle de l’infrastructure sous-jacente.
Les protocoles et technologies courants de surveillance du réseau incluent entre autre : SNMP (Simple Network Management Protocol), NetFlow, sFlow et syslog. Ils se retrouvent dans des produits aussi divers que Grafana/Prometheus, Zabbix, sFlow-RT, ntopng, Graylog…
La surveillance du réseau nécessite généralement une intervention humaine pour établir le comportement normal du réseau et du trafic. Ensuite, des outils de surveillance identifient et alertent les équipes sur les modifications du comportement attendu. Par exemple, les équipes peuvent utiliser SNMP pour référencer le comportement de débit d’une liaison réseau critique au fil du temps. Une fois que les administrateurs ont déterminé le comportement de base, l’outil de surveillance peut les alerter lorsque le comportement de débit dépasse ce qui est typique.
Continuer la lecture de « Observabilité du réseau (part.1) »