Dernière modification le 17 novembre 2021
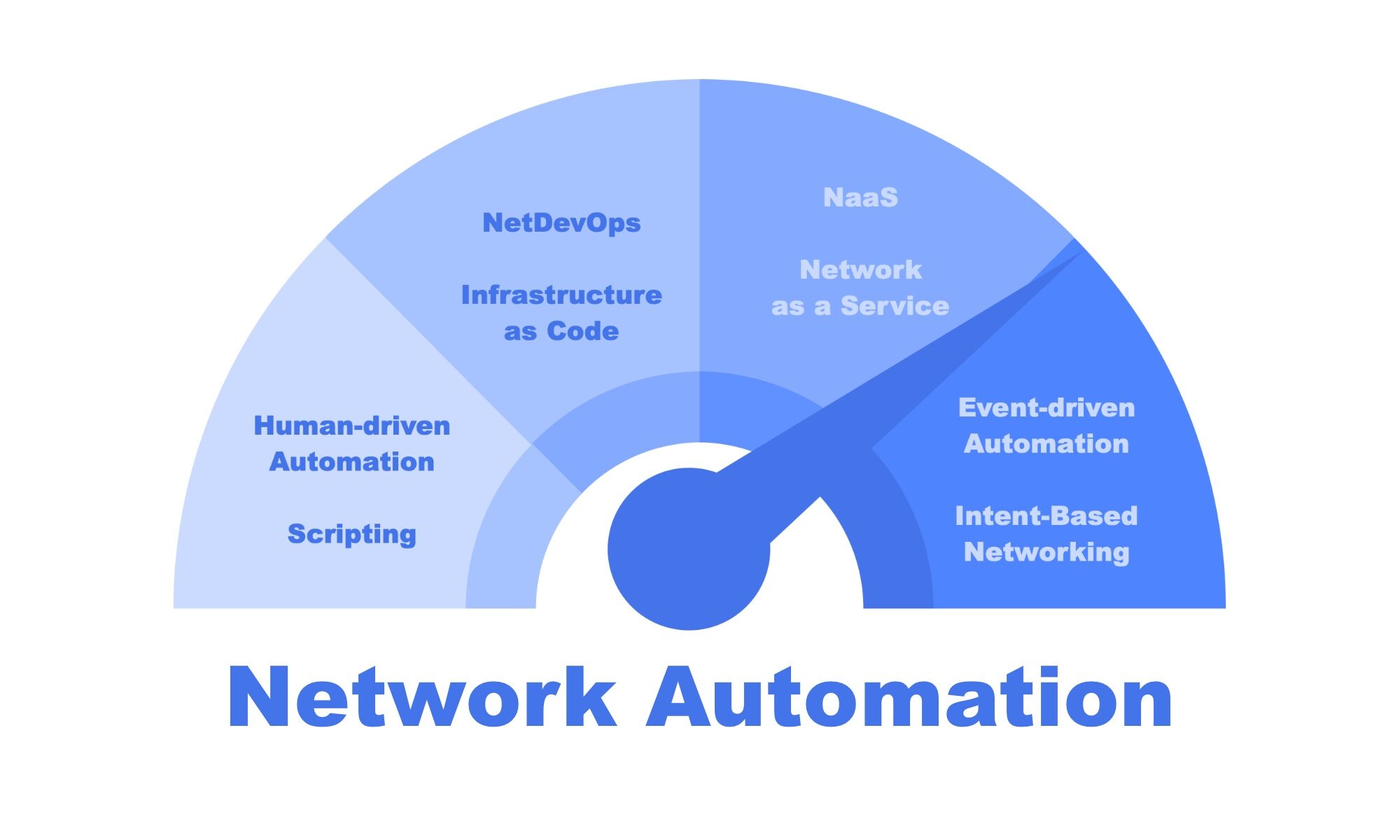
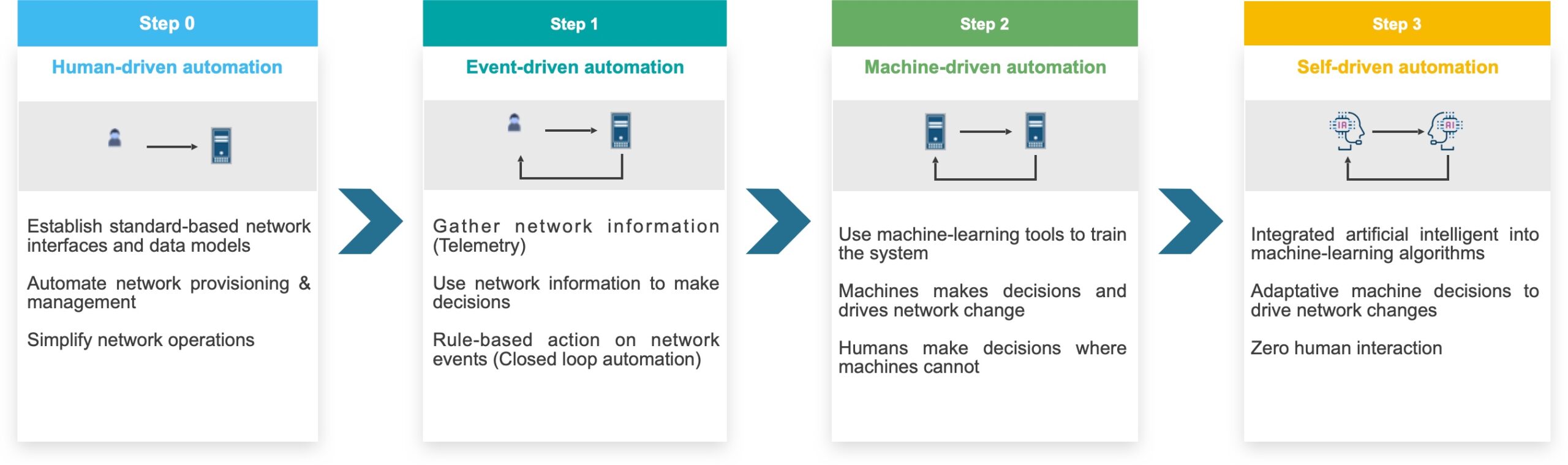
Je le répète assez souvent : « l’Intelligence Artificielle peut nous rendre des services dans le NetDevOps » pour résoudre des problèmes qui nécessiteraient des algorithmes très longs basés sur des successions de tests. Pour illustrer concrètement ces propos, je vous propose d’étudier un cas simple d’application de l’apprentissage automatique.
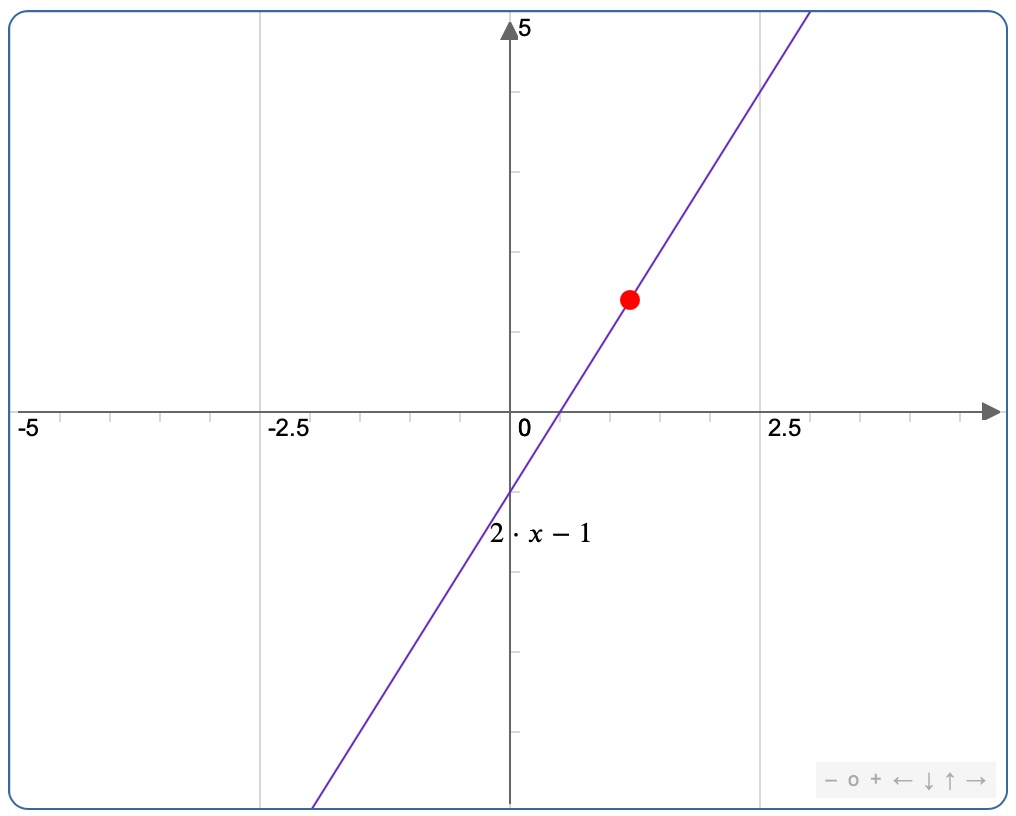
Prenons un exemple qui pourrait parfaitement faire partie d’un test de QI. Soit la suite de nombre suivante :
| X | -1 | 0 | 1 | 2 | 3 | 4 | 5 |
| Y | -3 | -1 | 1 | 3 | 5 | 7 | ? |
Compléter la dernière valeur de Y manquante…
Pour résoudre ce problème, il va falloir trouver la relation qui relie X et Y et une fois trouvée, l’appliquer à la valeur manquante. Un oeil un peu entrainé va rapidement voir que la relation est Y = 2X – 1
Par soucis de validation, on pourra l’appliquer à chacun des X pour vérifier qu’on a trouvé la relation avec certitude. Une fois validée, la relation sera appliquée à la dernière valeur de X pour trouver Y = 9. Cette relation pourrait s’appliquer à de nouvelles valeurs de X.