Consultant Sénior en Infrastructures Réseaux et Méthodologies, Conférencier, Formateur, Coach NetDevOps, Membre de Jurys d’Examens. Impliqué dans des projets de recherche et de développement, membre d'organismes de standardisation et de normalisation. Passionné par l'acquisition des connaissances et leur partage qui est un accélérateur d'apprentissage personnel, que ce soit dans les technologies, dans les méthodologies ou dans les matières composant le socle de base nécessaire au franchissement des différents niveaux de compétences.
Les étapes alpha et bêta sont terminées, mon Appliance Automation v2.0 est finie. Le brevet prévoyait déjà une fragmentation de la solution. Dans la version v1.0, ce sont les fonctions qui étaient fragmentées, mais la solution matérielle reposait sur un serveur unique. Dans la version v2.0, la partie matérielle a été répartie sur plusieurs serveurs, ce qui rend la solution facilement évolutive par ajout de modules.
Pour des constructeurs du monde de l’automatisation, accéder aux informations de configurations est souvent synonyme d’analyser les chaînes de caractères retournées pour les formater à l’affichage et y chercher des éléments ciblés. Par exemple, le module Python TextFSM a été mis au point pour permettre l’accès par programme aux informations renvoyées par l’interface de ligne de commande (CLI) des équipements réseau.
Dans le cas de Juniper Networks, Junos possède un ensemble complet d’API : API XML (accessible localement ou à distance en utilisant le protocole sécurisé NETCONF), API REST et API JET. Il existe donc plusieurs façons d’accéder avec certitude et de façon structurée aux éléments souhaités.
Les processus les plus importants pour l’automatisation de Junos sont les processus de service mgd et JET (jsd). Mgd gère les demandes d’automatisation impliquant l’API XML de Junos, YANG, l’API REST et certaines fonctions SNMP. Le processus de service JET (jsd) gère les demandes d’automatisation qui utilisent l’API JET (Juniper Extension Toolkit). Le processus de gestion (mgd) est au cœur de toute automatisation Junos basée sur NECTONF. L’interface de ligne de commande de Junos est également gérée par le biais de mgd.
La version 2.0 de mon appliance EVE-NG reprend le même serveur bare metal pour faire tourner EVE-NG, mais rajoute un étage sur la base d’un autre serveur, fabriqué à partir du concept de ma nouvelle « Appliance Automation », proposant une fonction DHCP pour distribuer des adresses IP aux personnes utilisant l’appliance via une connexion filaire ou Wi-Fi 5 (vitesse 1,3 Gbps en 5 GHz avec un canal de 80 MHz).
Au début des années 2010, je cherchai une solution pour construire un générateur de trafic Ethernet à haut débit pour des tailles de paquets de 64 octets et le moins cher possible afin de mettre en œuvre le RFC2544. Après de nombreuses approches et de nombreux développements qui n’ont abouti à rien de significatif, c’est en 2014 que la question du générateur de trafic pour tester les matériels en maquette est devenue cruciale. La référence dans ce domaine était Ixia, mais ceux qui connaissent les prix comprennent que ce n’était pas une solution accessible à tout le monde. Dans le domaine commercial, un de ses concurrents intéressant et dont j’ai suivi la progression était Xena. L’avantage de ces solutions n’était pas tant la puissance des générateurs mais le niveau d’intégration et de finition de la couche logicielle qui permettait de lancer facilement des tests conformes aux standards.
L’époque des matériels actifs de spare utilisés pour faire un incubateur servant à simuler un réseau est totalement révolue pour tous les constructeurs leaders du domaine de l’automatisation. Les simulateurs réseau permettent de réaliser virtuellement un réseau.
Il ne faut pas confondre un simulateur et un émulateur. Un simulateur permet de faire tourner une version virtuelle d’un matériel actif (commutateur, routeur, firewall, …) grâce à la virtualization, alors qu’un émulateur reproduit un comportement sans pour autant avoir des versions virtuelles des appareils. Pour illustrer ces propos avec deux exemples très connus, GNS3 est un simulateur alors que Packet Tracer est un émulateur.
Une question fréquente consiste à se demander quel est le meilleur simulateur… Je pense qu’il n’y a pas de réponse valide à cette question. Tout dépend de l’usage qu’on est amené à en faire et au contexte dans lequel on l’utilise. Personnellement j’en utilise trois en fonction des objectifs.
En 2016 j’ai écrit le module alcatel_aos pour Netmiko. Depuis, ce module Python fonctionne pour AOS6 et AOS8 et il est maintenu par Kirk Byers lorsque des changements majeurs sont effectués sur la librairie Netmiko.
Lorsqu’il s’agit de faire appel à Netmiko pour réaliser de l’automatisation sur OmniSwitch ALE, j’y adjoins le framework d’automatisation Nornir écrit en Python.
Docker est un système de gestion de conteneurs incontournable dans le domaine du NetDevOps. La notion de conteneur est utilisée pour faire tourner une application de manière isolée et légère sur l’hôte sur lequel Docker est installé. L’accès aux services internes au conteneur se fait par une redirection de ports sur l’hôte qui fait tourner Docker.
La première préoccupation qui apparaît, avec la notion de conteneur, est la persistance des données. En effet, lorsque le conteneur est détruit, les données sont détruites avec lui. Si ce comportement peut être voulu pour repartir facilement d’une base vierge, il est des cas dans lesquels on veut garder l’historique des données. Pour palier à cela, il est facile d’utiliser la notion de volume, en les stockant dans un répertoire spécifique du serveur hôte Docker plutôt que dans le système de fichiers par défaut du conteneur. Ce stockage externe, appelé volume de données, permet de rendre les données indépendantes de la vie du conteneur, soit en le créant de toute pièce, soit en faisant une correspondance entre un répertoire source existant sur l’hôte et le répertoire destination dans le conteneur. Le volume permet également de partager ces données entre plusieurs conteneurs sur un même hôte.
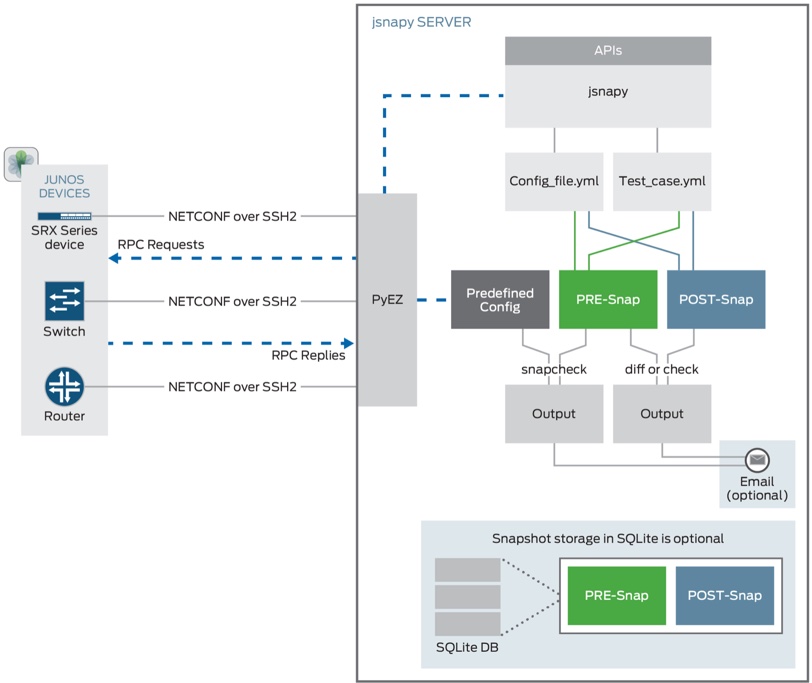
JSNAPy est un outil Open Source mis à disposition par Juniper. Il permet de valider la configuration d’un équipement et de comparer l’état d’une configuration avant et après une modification.
L’action peut être réalisée sur la configuration actuelle (snapcheck) ou sur le couple de configurations « avant et après » (PRE et POST).
Cet outil possède sa propre interface CLI pour être utilisé de façon autonome. Il est également possible de faire fonctionner JSNAPy à partir du modules Ansible galaxy juniper_junos_jsnapy ou directement à partir de scripts Python.
tests_include:
- test_interfaces_terse
test_interfaces_terse:
- rpc: get-interface-information
- iterate:
xpath: //physical-interface
id: './name'
tests:
- no-diff: description
err: "Test Failed! description for <{{id_0}}> got changed, before it was <{{pre['description']}}>, now it is <{{post['description']}}>"
info: "Test succeeded! description for <{{id_0}}> did not change, before it was <{{pre['description']}}>, now it is <{{post['description']}}>"
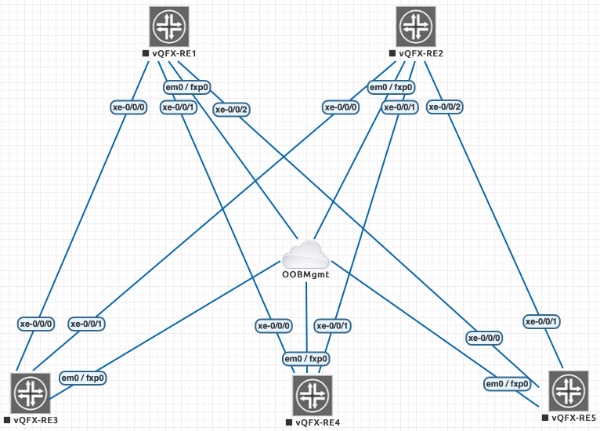
J’ai demandé une amélioration car le nom des fichiers snapshots est constitué avec l’adresse IP mais pas avec le port, et il n’est pas possible de changer le nom du fichier depuis un playbook Ansible utilisant juniper_junos_jsnappy. Lorsque JSNAPy est utilisé en environnement de simulation Vagrant, tous les devices ont la même adresse IP, ce n’est que le port qui les différencient. A suivre…
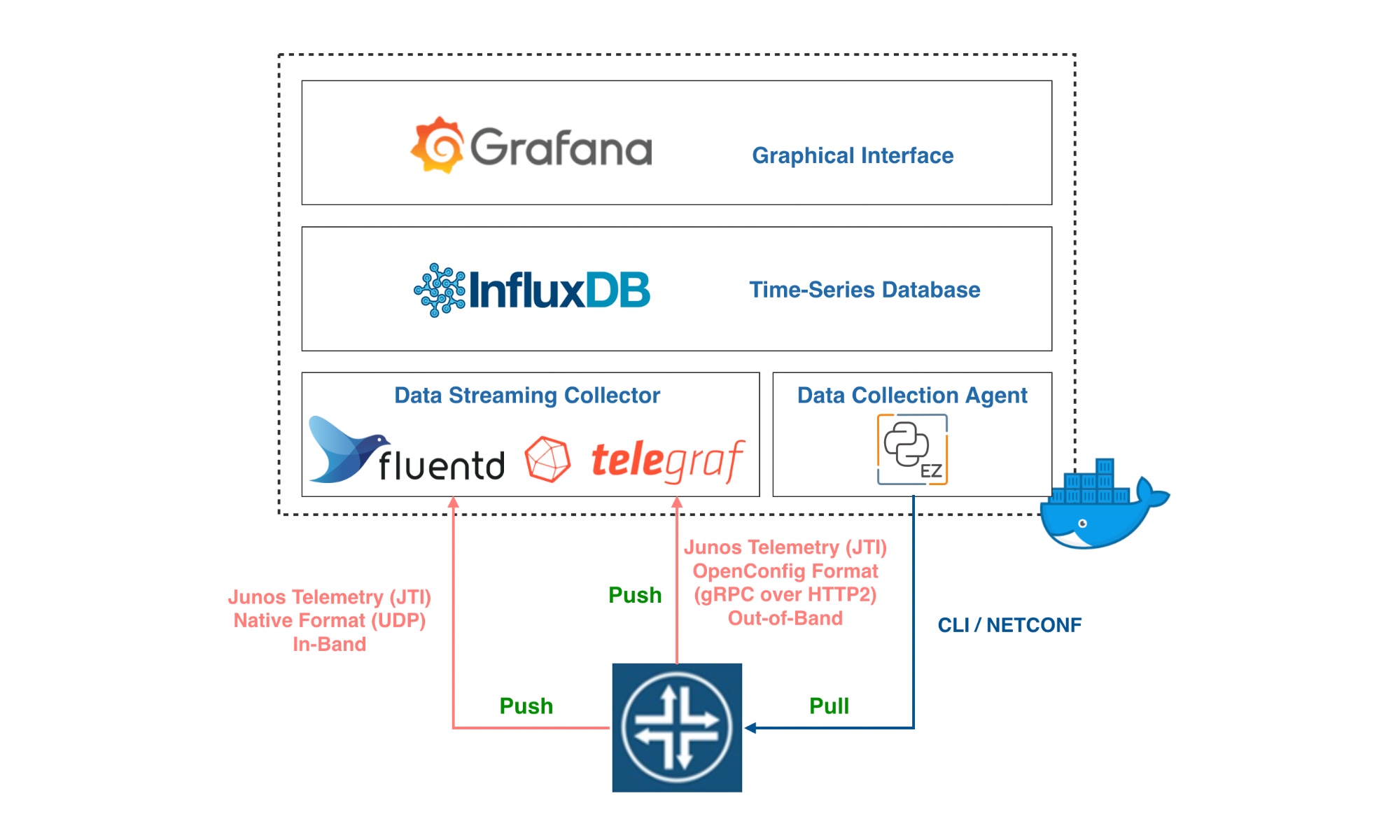
Le modèle traditionnel de monitoring de réseau est basé sur un modèle dit « pull », utilisant SNMP et CLI pour interroger périodiquement les équipements du réseau. Ces méthodes ont des limites inhérentes en matière d’évolutivité et sont gourmandes en ressources, en particulier lorsqu’un grand nombre de métriques sont interrogées à une fréquence très élevée.
JTI (Junos Telemetry Interface) contourne le problème et élimine le besoin de scrutation, en utilisant plutôt un modèle « push » pour transmettre les données de télémétrie à un collecteur de manière asynchrone sous forme de flux. Cette approche est beaucoup plus évolutive et prend en charge la surveillance de milliers d’objets dans un réseau avec une résolution granulaire.
Cependant, la collecte de données de télémétrie n’est pas une tâche aisée, car elle implique généralement trois types de fonctions :
Même si Ansible est très bien pour faire du Human-driven Automation face à des équipements Juniper, je trouve gratifiant et plus pratique de développer directement en Python. Comme je l’ai déjà expliqué, j’utilise le protocole NETCONF simplifié par le micro framework PyEZ. Je me sers de PyEZ de façon transparente au travers de NAPALM, lui même piloté par le framework Nornir.
Lorsque l’on écrit des scripts, il peut rapidement y en avoir une grande quantité très proches les uns des autres et qui ne font, chacun, qu’une seule fonction.
C’est pour cette raison, que je rajoute le package Python Click qui permet de réaliser des interfaces CLI (Command-Line Interface) enrichie, de manière à limiter le nombre de scripts.
Prenons comme exemple un script dont l’objectif serait de faire des napalm_get et napalm_configure avec un CLI simplifié.